| |
|
| A
chromatography data system is essentially a computer
running specialized software designed to integrate
chromatographic peaks and relate peak area or height to
the amount of analyte present on the basis of calibration
data. In many cases, the software will include additional
statistical and database capability for enhanced
analysis, storage, and reporting of information.
|
|
| In its most
fundamental form, a chromatogram is simply a plot or
record of a voltage signal as a function of time. In a
properly functioning UV detector (for example), this
voltage is directly proportional to the absorbance of the
effluent in the detector cell. Assuming that the Beer-Lambert
law holds, this absorbance will be directly proportional
to the concentration of the absorbing species (the
analyte); this means that the chromatogram is (indirectly)
a plot of sample concentration versus time. Assuming that
the mobile phase flow through the detector is constant,
the volume of mobile phase pumped will be directly
proportional to the elapsed time. Thus, the chromatogram
is (even more indirectly) a representation of
concentration versus volume. Measuring the area under the
peak amounts to measuring the product of concentration
times volume, which is proportional to the mass (or moles)
of analyte.
|
|
The term "integration"
refers to the process of measuring the area included
under a chromatographic peak. This is accomplished by
adding the voltage measurements made at equal time
intervals from the beginning to the end of the peak, then
subtracting a "correction trapezoid" to correct
for the offset of the chromatographic baseline from true
zero as well as baseline drift.
|
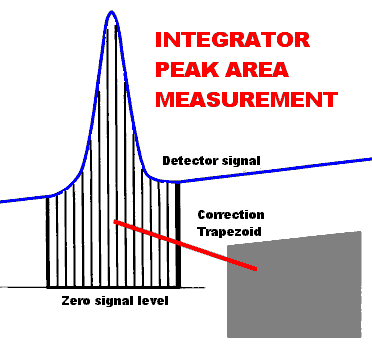
Integration is carried
out by summing voltage measurements made from the
beginning to the end of the peak then subtracting the
area of a correction trapezoid to account for non-zero
baseline.
|
| |
|
In order to
accomplish this task, the data system software must be
able to:
- damp out or otherwise
ignore random fluctuations in the signal ("baseline
noise")
- identify the beginning
of a peak
- identify the peak
maximum (the retention time of the peak)
- identify the end of
the peak
- compute the area of
the correction trapezoid.
|
|
| |
|
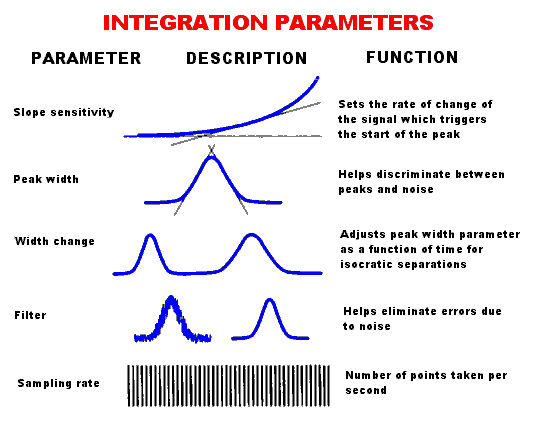
| Noise
reduction can be accomplished by either ignoring baseline
fluctuations smaller than a selected threshold or "time
averaging" the signal to damp out random
fluctuations. Although the threshold values or sampling
rates can be set manually, most data systems include some
sort of "auto tune" capability which sets the
appropriate parameters on the basis of an actual
measurement of baseline noise when the mobile phase is
flowing but before the sample has been injected. Likewise, the "slope
sensitivity" values for the beginning and ending of
the peaks can be automatically determined in most cases.
|
|
| |
|
|
|
| |
|
| Modern data
systems will either draw the calculated baselines or else
use markers to indicate the beginning and end of peak
integration. In most cases, the user can manually "force"
a baseline when the computer algorithm is obviously in
error (the human eye is surprisingly good at pattern
recognition!), but such manual intervention should be
avoided if possible in order to avoid the potential for
biased results. The
figure at the right shows three "predictable"
types of erroneous baseline assignments (dotted lines)
along with the correct integration of the peaks (red
shading).
|
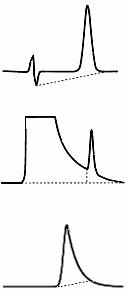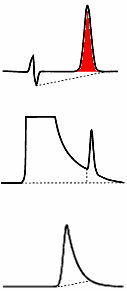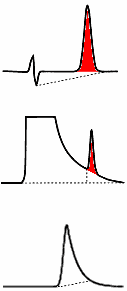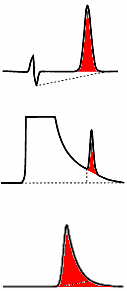
|
| |
|
| If the width
of a peak is constant from one chromatogram to another (this
is usually the case), then peak height may be used as a
surrogate for peak area. Peak height measurements are
more reliable for very small peaks or for chromatograms
in which resolution is marginal. Peak area is preferred
for very large peaks or where a wide linear range is
required.
|
|
| |
|